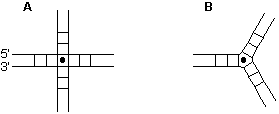
https://iubmb.qmul.ac.uk/misc/bran.html
World Wide Web version Prepared by G. P. Moss
School of Physical and Chemical Sciences, Queen Mary University of London,
Mile End Road, London, E1 4NS, UK
g.p.moss@qmul.ac.uk
These Rules are as close as possible to the published version prepared by David M. J. Lilley, Robert M. Clegg, Stephan Diekmann, Nadrian C. Seeman, Eberhard von Kitzing and Paul Hagerman [see Eur. J. Biochem., 1995, 230, 1-2; J. Mol. Biol.. 1996, 255, 554-555; Nucleic Acid Res.. 1995, 23, 3363-3364. Copyright IUBMB; reproduced with the permission of IUBMB]. If you need to cite these rules please quote these references as their source.
Any comments should be sent to any other member of the Committee
Introduction
Fully basepaired junctions
Duplexes with single-stranded sections
More complex junctions containing single-stranded sections
Other helical junctions
Tertiary interactions
Breaks in continuity
Branch migration
Branchpoints are a common feature of folded nucleic acids. They may be created from double-stranded DNA during processes generating sequence rearrangements such as homologous or site-specific recombination, or by the secondary and tertiary folding of single-stranded nucleic acids. The latter is especially important in RNA, and the branched structure of such molecules may be central to their function. The structures of branchpoints in DNA molecules are known to be recognised by a number of enzymes that may bind to and manipulate DNA junctions. As the complexity of the junctions studied in laboratories has increased, a need has arisen to find a nomenclature that will allow the unambiguous description of any given branchpoint.
We therefore propose a method for describing the connectivity of any branchpoint or junction in the secondary structure of a nucleic acid. Such a branchpoint forms the point of connection between a number of different helical segments, with or without the inclusion of formally single-stranded regions.
At a chosen place in the molecule, write a dot . about which we will describe the connectivity. Then pass 360o about this dot, through either backbone or basepair (suggested direction 5' to 3' through backbone. i.e. clockwise as drawn below). Write H for each helix and S for a single-stranded section traversed. Basepairs are viewed from their minor groove side. Choose a startpoint to maximise the initial number of helices. Single-stranded sections may have a subscript indicating the number of unpaired bases.
According to the scheme, the simple four-way junction (A) becomes HHHH. which could be shortened to 4H. while the three-way junction (B) becomes HHH or 3H. An additional possibility might be to indicate the length of the helix as a subscript. e.g. a three-way junction comprising three arms each of 10 base pairs might be described by 3H10. However, this remains optional because the length of the helix may be ambiguous (these helices can have their own features such as bulges and bubbles), or even unknown.
Duplexes with single-stranded sections

Here we have two molecules with base bulges (C and D). and a duplex interrupted by a single-stranded bubble, or internal loop (E). According to the rules, the bulged duplexes becomes 2HS1 (molecule C) and 2HS3 (molecule D), while the bubble becomes HS3HS4. An extra rule is introduced where there are multiple single-stranded regions - the start point is chosen so that the shorter single-stranded region is written first. A single-base mismatch could be described by the formal description HS1HS1
More complex junctions containing single-stranded sections
These will be described using an addition to these rules. They will be written so as to place the maximum number of helical sections first. Taking the examples of three and four-way junctions with one or more single-stranded sections:
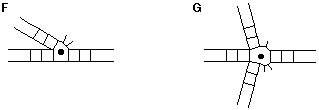
According to the rules, junction (F) becomes 3HS2, while junction (G) is described by 3HS1HS1.
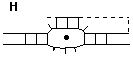
In principle, this method could be extended to include other types of helical junction. For example, the interface between a section of right-handed B-DNA and one of left-handed Z-DNA might be described by HBHZ. H would be retained as a conventionally basepaired duplex of unspecified character.
The single-stranded sections (loops or bulges) might make long-range interactions, such as the formation of pseudoknots. The resulting double-stranded sections will be indicated either by D or by Dn. where n is the number of base pairs (if unambiguous). Thus a typical pseudoknot
In some cases the path around the point may be broken at some point, by a nick in the backbone. This could be indicated by a slash /; e.g. the junction
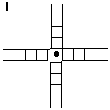
In some structures, notably the four-way junction. some sequences can undergo branch migration. It is hard to allow explicitly for this, although unless arm lengths are specified this need not alter the formal description of the junction. But it should be borne in mind that in some circumstances the formal description might apply only to one isomer of a given structure.